Intel® Tiber™ Broadcast Suite#
[!TIP] Full Documentation for Intel® Tiber™ Broadcast Suite.
![]()
![]()
![]()
![]()
![]()
1. Overview#
The Intel® Tiber™ Broadcast Suite, is a software-based package, modular video production pipeline, designed for creation of high-performance and high-quality solutions used in live video production. The video pipelines are built using Intel-optimized version of FFmpeg and combine: media transport protocols (SMPTE ST 2110-compliant), JPEG XS encoding/decoding, GPU media processing and rendering.
2. Intel® Tiber™ Broadcast Suite#
2.1. High level components description#
The Intel® Tiber™ Broadcast Suite uses the open-source FFmpeg framework as a baseline and enhances it with the following components:
Media Transport Library (MTL): Implements SMPTE ST 2110 transport protocols with support for yuv422p10le and y210le pixel formats. It ensures ultra-low latency and high-performance media transport.
Media Communications Mesh: Provides a scalable and efficient framework for managing media communication workflows, enabling seamless integration of multiple media streams with low latency and high reliability. Media Communications Mesh supports advanced features such as dynamic stream routing, adaptive bitrate control, and real-time synchronization across distributed systems.
Intel® QSV and OneVPL libraries: Enable hardware-accelerated media processing using Intel Flex GPU cards for encoding, decoding, and transcoding.
SVT AV1 Codec Support: The suite integrates the Scalable Video Technology for AV1 (SVT-AV1) codec, enabling high-performance, scalable, and efficient AV1 encoding and decoding for modern video streaming and broadcast applications.
JPEG-XS Codec Support: Includes support for JPEG-XS, a low-latency, visually lossless codec optimized for professional video production workflows, ensuring high-quality compression and decompression for live video streams.
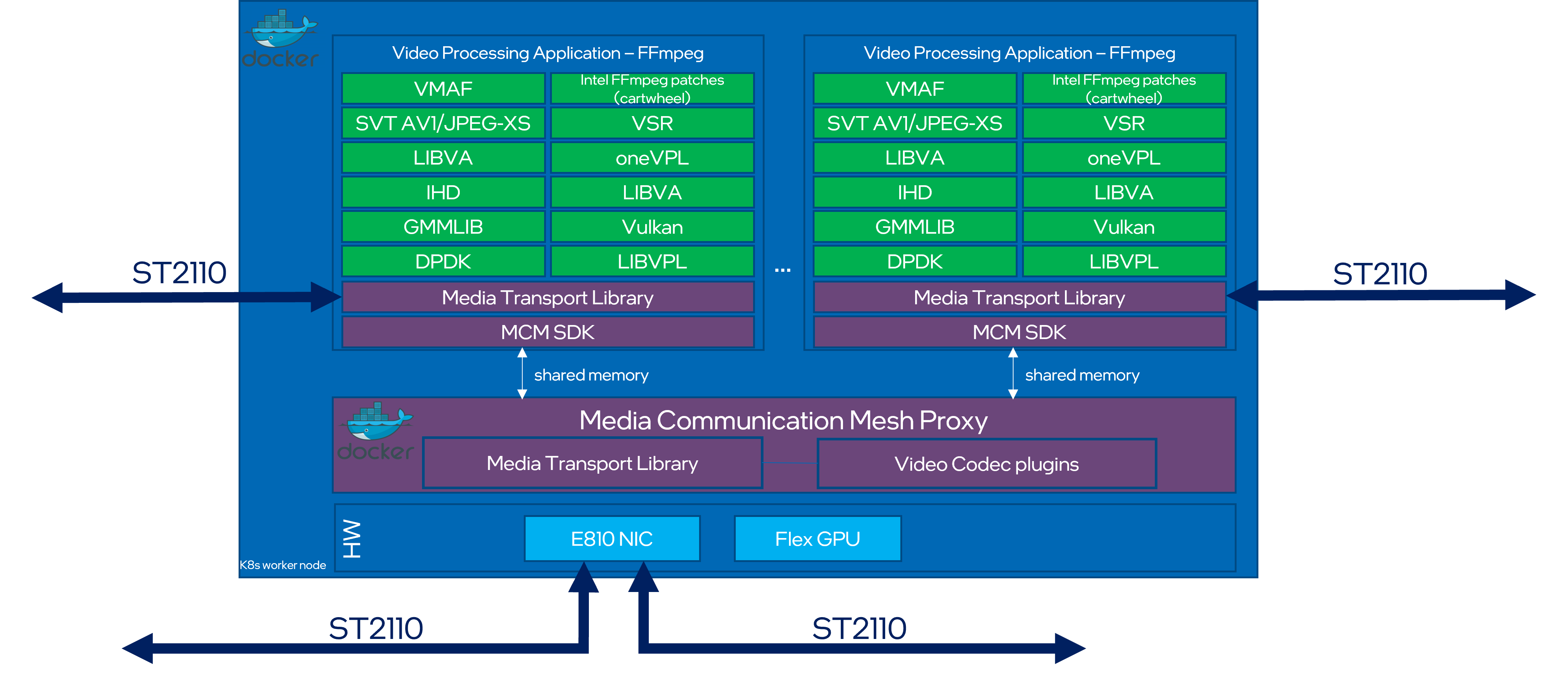
The architecture, as depicted in above diagram, highlights the modular design of the suite, which includes:
Input Sources: The suite supports multiple input sources, including IP streams (SMPTE ST 2110), and file-based media.
Processing Pipelines: The pipelines leverage Intel-optimized FFmpeg with MTL for media transport, Intel QSV for hardware acceleration
Output Targets: Outputs include IP streams, and file-based formats, ensuring compatibility with various broadcast and production workflows.
Control Plane: The control plane integrates with NMOS IS-04/IS-05 for device discovery and connection management, enabling seamless orchestration of media workflows.
Monitoring and Analytics: Real-time monitoring and analytics are supported to ensure high-quality media delivery and performance optimization.
The software package also includes several performance optimizations:
Memory Management: Page-aligned surface allocations for efficient memory usage.
Asynchronous Execution: Video pipeline filters execute asynchronously to maximize GPU utilization.
High-throughput Data Transfers: Optimized GPU-CPU memory transfers for high-performance processing.
This modular architecture ensures flexibility, scalability, and high performance for live video production environments.
2.2. Media Transport Library (MTL) for Intel® Tiber™ Broadcast Suite#
Lockless Design: MTL employs a lockless design in the data plane, utilizing busy polling (busy-waiting or spinning) to achieve ultra-high performance and low latency. This technique constantly checks for new data packets, minimizing latency and avoiding costly context switches between the kernel and user space.
Tasklet Scheduler: MTL incorporates an asynchronous tasklet scheduler, allowing efficient utilization of the pinned polling thread. Tasklets are lightweight functions that run in the context of the pinned thread, enabling more efficient use of the Last Level Cache (LLC) at different processing stages.
Session Migration: MTL supports session migration with the ability to redistribute overloaded sessions to underutilized schedulers at runtime, adding flexibility to deployment and accommodating unpredictable system capacity.
Zero-Copy Packet Build: MTL leverages the multi-buffer descriptor feature of modern NICs to achieve zero-copy transmission when using DPDK Poll Mode Drivers (PMDs), delivering unparalleled performance with a single core capable of sending approximately 50 Gbps.
ST 2110-21 Pacing: MTL addresses the stringent timing requirements of ST 2110-21 through a software-based approach, combining NIC rate-limiting features with a software algorithm, successfully passing numerous third-party interoperability verifications.
Huge Page Memory Management: MTL utilizes hugepages for performance optimization, reducing TLB misses, improving cache usage, and avoiding page faults, thereby enhancing packet processing efficiency.
Comprehensive Control Protocols: MTL implements specific control protocols, including
ARP,IGMP,DHCP, andPTP, to support theDPDK Poll Mode Driver'snature of bypassing the kernel.Flexible API and Ecosystem: MTL offers a comprehensive API and ecosystem, including frame mode, slice mode, RTP passthrough mode, pipeline mode, and support for
ST2022-6,ST2110-22JPEG XS,redundancy,interlaced video, and more, enabling seamless integration with popular media frameworks like FFMPEG, OBS, and Intel® Media SDK.Runtime Configuration: MTL allows runtime updates to source and destination addresses, enabling dynamic reconfiguration without the need for session recreation, providing significant flexibility in switch/forward scenarios.
Timing Parser and Analysis: MTL provides utilities for verifying the compliance of incoming ST 2110-20 RX streams with the ST 2110 standard, including a built-in status report, detailed parsing results, and a sample timing parser UI constructed using Python bindings.
2.3. Intel® Library for Video Super Resolution (RAISR) for Intel® Tiber™ Broadcast Suite#
Intel’s Library for Video Super Resolution stands out as a high-performance, highly customizable, and efficient solution for video upscaling and sharpening, leveraging Intel’s cutting-edge hardware and software technologies, while offering seamless integration with industry-standard tools and fostering an open-source community.

Rapid and Accurate Image Super Resolution: Intel’s Library for Video Super Resolution (Intel Library for VSR) is a cutting-edge solution that leverages the RAISR (Rapid and Accurate Image Super Resolution) algorithm, a public AI-based algorithm known for its superior quality and efficient performance-quality trade-off compared to other deep learning-based algorithms like EDSR.
Intel® Advanced Vector Extension 512: Intel has enhanced the RAISR algorithm to achieve better visual quality and beyond real-time performance for 2x and 1.5x upscaling on Intel Xeon platforms and Intel GPUs, taking advantage of Intel Advanced Vector Extension 512 (Intel AVX-512) and the newly added Intel AVX-512FP16 support on Intel Xeon 4th Generation (Sapphire Rapids) processors.
C++ Optimal Performance: The Intel Library for VSR is provided as an FFmpeg plugin inside a Docker container (CPU only), simplifying testing and deployment efforts, and is developed using C++ for optimal performance.
Advanced customization options: The library offers advanced customization options, including thread count adjustment, filter folder selection for different training parameters and datasets, bit depth support (8-bit and 10-bit), color range control, blending modes, multi-pass processing, and assembly instruction set selection (AVX-512FP16, AVX-512, AVX2, or OpenCL).
Census Transform (CT) and Difference of Gaussians (DoG): Intel’s implementation of the RAISR algorithm includes a novel, highly efficient, and effective sharpening algorithm based on the Census Transform (CT) and Difference of Gaussians (DoG) filters, capable of enhancing a wide range of frequencies while avoiding common sharpening artifacts like halos and noise amplification.
Intel GPUs through OpenCL: The Intel Library for VSR supports hardware acceleration on Intel GPUs through OpenCL, as well as integration with FFmpeg-QSV and FFmpeg-VAAPI for efficient video processing pipelines.
BSD 3-Clause: Intel’s commitment to open-source and community contributions is evident, as the project is hosted on GitHub, and contributions are welcomed under the BSD 3-Clause “New” or “Revised” license.
3. Build Instructions#
3.1. Quick Start#
To configure your system and build the Intel® Tiber™ Broadcast Suite image, please refer to the build guide.
4. High level usage examples#
How to run and example usage of the Intel® Tiber™ Broadcast Suite run guide.
5. How to Contribute#
We welcome community contributions to the Intel® Tiber™ Broadcast Suite project. If you have any ideas or issues, please share them with us by using GitHub issues or opening a pull request.
5.1. Fork this repository#
Before opening a pull request, please follow these steps:
Fork this repository to your own space.
Create a new branch for your changes.
Make your changes and commit them.
Push your changes to your forked repository.
Open a pull request to the main repository.
5.2. Coding style#
We use linters for style checks.
5.2.1. Linter example#
Please check with the following example command inside the Docker container for linters:
# super-linter
docker run -it --rm -v "$PWD":/opt/ --entrypoint /bin/bash github/super-linter
cd /opt/
# echo "shfmt check"
find ./ -type f -name "*.sh" -exec shfmt -w {} +
# echo "shell check"
find ./ -name "*.sh" -exec shellcheck {} \;
# hadolint check
hadolint Dockerfile
# markdownlint check
find ./ -name "*.md" -exec markdownlint {} \;
# find ./ -name "*.md" -exec markdownlint {} --fix \;
# textlint
find ./ -name "*.md" -exec textlint {} \;
# find ./ -name "*.md" -exec textlint {} --fix \;
Note#
This project is under development. All source code and features on the main branch are for the purpose of testing or evaluation and not production ready.